


“Fragments” of Yandex’s codebase leaked on-line final week. Very like Google, Yandex is a platform with many points akin to e-mail, maps, a taxi service, and so on. The code leak featured chunks of all of it.
In keeping with the documentation therein, Yandex’s codebase was folded into one giant repository referred to as Arcadia in 2013. The leaked codebase is a subset of all tasks in Arcadia and we discover a number of elements in it associated to the search engine within the “Kernel,” “Library,” “Robotic,” “Search,” and “ExtSearch” archives.
The transfer is wholly unprecedented. Not for the reason that AOL search question information of 2006 has one thing so materials associated to an internet search engine entered the general public area.
Though we’re lacking the information and lots of information which can be referenced, that is the primary occasion of a tangible have a look at how a contemporary search engine works on the code degree.
Personally, I can’t recover from how unbelievable the timing is to have the ability to really see the code as I end my guide “The Science of Web optimization” the place I’m speaking about Info Retrieval, how fashionable engines like google really work, and methods to construct a easy one your self.
In any occasion, I’ve been parsing by way of the code since final Thursday and any engineer will let you know that’s not sufficient time to grasp how all the things works. So, I believe there can be a number of extra posts as I preserve tinkering.
Earlier than we soar in, I need to give a shout-out to Ben Wills at Ontolo for sharing the code with me, pointing me within the preliminary course of the place the good things is, and going forwards and backwards with me as we deciphered issues. Be happy to seize the spreadsheet with all the information we’ve compiled concerning the rating components right here.
Additionally, shout out to Ryan Jones for digging in and sharing some key findings with me over IM.
OK, let’s get busy!
It’s not Google’s code, so why can we care?
Some consider that reviewing this codebase is a distraction and that there’s nothing that can affect how they make enterprise choices. I discover that curious contemplating these are folks from the identical Web optimization group that used the CTR mannequin from the 2006 AOL information because the business normal for modeling throughout any search engine for a few years to observe.
That stated, Yandex will not be Google. But the 2 are state-of-the-art net engines like google which have continued to remain on the reducing fringe of know-how.
Software program engineers from each firms go to the identical conferences (SIGIR, ECIR, and so on) and share findings and improvements in Info Retrieval, Pure Language Processing/Understanding, and Machine Studying. Yandex additionally has a presence in Palo Alto and Google beforehand had a presence in Moscow.
A fast LinkedIn search uncovers just a few hundred engineers which have labored at each firms, though we don’t know what number of of them have really labored on Search at each firms.
In a extra direct overlap, Yandex additionally makes utilization of Google’s open supply applied sciences which have been essential to improvements in Search like TensorFlow, BERT, MapReduce, and, to a a lot lesser extent, Protocol Buffers.
So, whereas Yandex is definitely not Google, it’s additionally not some random analysis venture that we’re speaking about right here. There’s a lot we are able to study how a contemporary search engine is constructed from reviewing this codebase.
On the very least, we are able to disabuse ourselves of some out of date notions that also permeate Web optimization instruments like text-to-code ratios and W3C compliance or the final perception that Google’s 200 alerts are merely 200 particular person on and off-page options reasonably than courses of composite components that probably use 1000’s of particular person measures.
Some context on Yandex’s structure
With out context or the power to efficiently compile, run, and step by way of it, supply code may be very tough to make sense of.
Sometimes, new engineers get documentation, walk-throughs, and have interaction in pair programming to get onboarded to an current codebase. And, there may be some restricted onboarding documentation associated to establishing the construct course of within the docs archive. Nevertheless, Yandex’s code additionally references inside wikis all through, however these haven’t leaked and the commenting within the code can be fairly sparse.
Fortunately, Yandex does give some insights into its structure in its public documentation. There are additionally a few patents they’ve revealed within the US that assist shed a bit of sunshine. Particularly:
As I’ve been researching Google for my guide, I’ve developed a a lot deeper understanding of the construction of its rating programs by way of varied whitepapers, patents, and talks from engineers couched in opposition to my Web optimization expertise. I’ve additionally spent loads of time sharpening my grasp of normal Info Retrieval greatest practices for net engines like google. It comes as no shock that there are certainly some greatest practices and similarities at play with Yandex.

Yandex’s documentation discusses a dual-distributed crawler system. One for real-time crawling referred to as the “Orange Crawler” and one other for normal crawling.
Traditionally, Google is alleged to have had an index stratified into three buckets, one for housing real-time crawl, one for often crawled and one for not often crawled. This method is taken into account a greatest apply in IR.
Yandex and Google differ on this respect, however the normal thought of segmented crawling pushed by an understanding of replace frequency holds.
One factor price calling out is that Yandex has no separate rendering system for JavaScript. They are saying this of their documentation and, though they’ve Webdriver-based system for visible regression testing referred to as Gemini, they restrict themselves to text-based crawl.
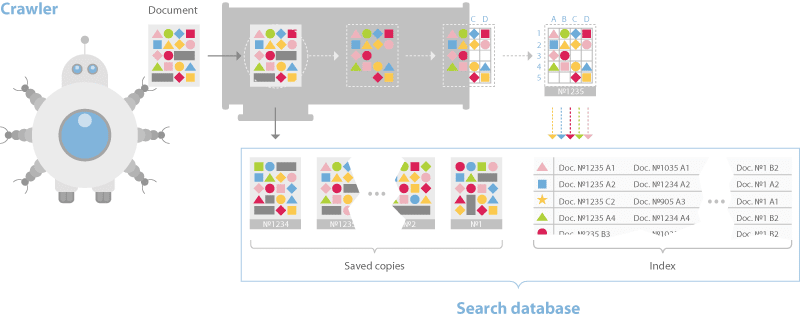
The documentation additionally discusses a sharded database construction that breaks pages down into an inverted index and a doc server.
Identical to most different net engines like google the indexing course of builds a dictionary, caches pages, after which locations information into the inverted index such that bigrams and trigams and their placement within the doc is represented.
This differs from Google in that they moved to phrase-based indexing, that means n-grams that may be for much longer than trigrams a very long time in the past.
Nevertheless, the Yandex system makes use of BERT in its pipeline as nicely, so in some unspecified time in the future paperwork and queries are transformed to embeddings and nearest neighbor search methods are employed for rating.

The rating course of is the place issues start to get extra fascinating.
Yandex has a layer referred to as Metasearch the place cached standard search outcomes are served after they course of the question. If the outcomes will not be discovered there, then the search question is shipped to a collection of 1000’s of various machines within the Fundamental Search layer concurrently. Every builds a posting record of related paperwork then returns it to MatrixNet, Yandex’s neural community utility for re-ranking, to construct the SERP.
Primarily based on movies whereby Google engineers have talked about Search’s infrastructure, that rating course of is kind of much like Google Search. They discuss Google’s tech being in shared environments the place varied functions are on each machine and jobs are distributed throughout these machines primarily based on the provision of computing energy.
One of many use circumstances is precisely this, the distribution of queries to an assortment of machines to course of the related index shards shortly. Computing the posting lists is the primary place that we have to think about the rating components.
There are 17,854 rating components within the codebase
On the Friday following the leak, the inimitable Martin MacDonald eagerly shared a file from the codebase referred to as web_factors_info/factors_gen.in. The file comes from the “Kernel” archive within the codebase leak and options 1,922 rating components.
Naturally, the Web optimization group has run with that quantity and that file to eagerly unfold information of the insights therein. Many of us have translated the descriptions and constructed instruments or Google Sheets and ChatGPT to make sense of the information. All of that are nice examples of the ability of the group. Nevertheless, the 1,922 represents simply one in all many units of rating components within the codebase.

A deeper dive into the codebase reveals that there are quite a few rating issue information for various subsets of Yandex’s question processing and rating programs.
Combing by way of these, we discover that there are literally 17,854 rating components in complete. Included in these rating components are a wide range of metrics associated to:
- Clicks.
- Dwell time.
- Leveraging Yandex’s Google Analytics equal, Metrika.
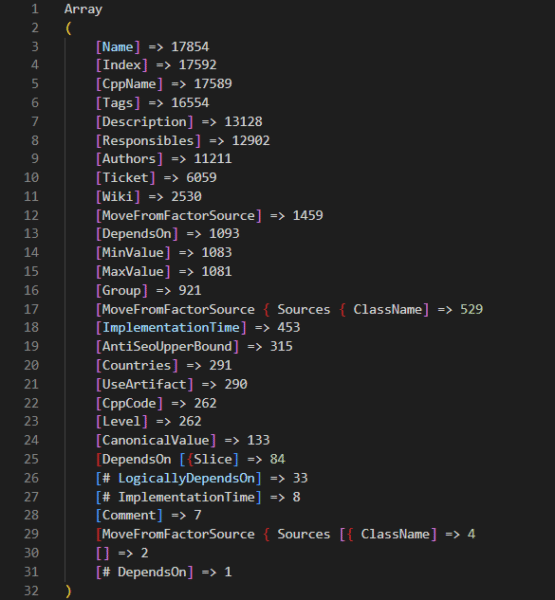
There’s additionally a collection of Jupyter notebooks which have an extra 2,000 components exterior of these within the core code. Presumably, these Jupyter notebooks characterize checks the place engineers are contemplating extra components so as to add to the codebase. Once more, you may evaluate all of those options with metadata that we collected from throughout the codebase at this hyperlink.

Yandex’s documentation additional clarifies that they’ve three courses of rating components: Static, Dynamic, and people associated particularly to the consumer’s search and the way it was carried out. In their very own phrases:

Within the codebase these are indicated within the rank components information with the tags TG_STATIC and TG_DYNAMIC. The search associated components have a number of tags akin to TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH, and TG_USER_SEARCH_ONLY.
Whereas now we have uncovered a possible 18k rating components to select from, the documentation associated to MatrixNet signifies that scoring is constructed from tens of 1000’s of things and customised primarily based on the search question.

This means that the rating surroundings is extremely dynamic, much like that of Google surroundings. In keeping with Google’s “Framework for evaluating scoring features” patent, they’ve lengthy had one thing related the place a number of features are run and the perfect set of outcomes are returned.
Lastly, contemplating that the documentation references tens of 1000’s of rating components, we must also understand that there are a lot of different information referenced within the code which can be lacking from the archive. So, there may be probably extra occurring that we’re unable to see. That is additional illustrated by reviewing the pictures within the onboarding documentation which reveals different directories that aren’t current within the archive.

For example, I believe there may be extra associated to the DSSM within the /semantic-search/ listing.
The preliminary weighting of rating components
I first operated underneath the belief that the codebase didn’t have any weights for the rating components. Then I used to be shocked to see that the nav_linear.h file within the /search/relevance/ listing options the preliminary coefficients (or weights) related to rating components on full show.
This part of the code highlights 257 of the 17,000+ rating components we’ve recognized. (Hat tip to Ryan Jones for pulling these and lining them up with the rating issue descriptions.)
For readability, if you consider a search engine algorithm, you’re in all probability pondering of a protracted and complicated mathematical equation by which each and every web page is scored primarily based on a collection of things. Whereas that’s an oversimplification, the next screenshot is an excerpt of such an equation. The coefficients characterize how essential every issue is and the ensuing computed rating is what could be used to attain selecter pages for relevance.

These values being hard-coded means that that is definitely not the one place that rating occurs. As a substitute, this perform is almost certainly the place the preliminary relevance scoring is completed to generate a collection of posting lists for every shard being thought of for rating. Within the first patent listed above, they discuss this as an idea of query-independent relevance (QIR) which then limits paperwork previous to reviewing them for query-specific relevance (QSR).
The ensuing posting lists are then handed off to MatrixNet with question options to check in opposition to. So whereas we don’t know the specifics of the downstream operations (but), these weights are nonetheless useful to grasp as a result of they let you know the necessities for a web page to be eligible for the consideration set.
Nevertheless, that brings up the subsequent query: what can we learn about MatrixNet?
There’s neural rating code within the Kernel archive and there are quite a few references to MatrixNet and “mxnet” in addition to many references to Deep Structured Semantic Fashions (DSSM) all through the codebase.
The outline of one of many FI_MATRIXNET rating issue signifies that MatrixNet is utilized to all components.
Issue {
Index: 160
CppName: “FI_MATRIXNET”
Title: “MatrixNet”
Tags: [TG_DOC, TG_DYNAMIC, TG_TRANS, TG_NOT_01, TG_REARR_USE, TG_L3_MODEL_VALUE, TG_FRESHNESS_FROZEN_POOL]
Description: “MatrixNet is utilized to all components – the formulation”
}
There’s additionally a bunch of binary information which may be the pre-trained fashions themselves, however it’s going to take me extra time to unravel these points of the code.
What is straight away clear is that there are a number of ranges to rating (L1, L2, L3) and there may be an assortment of rating fashions that may be chosen at every degree.
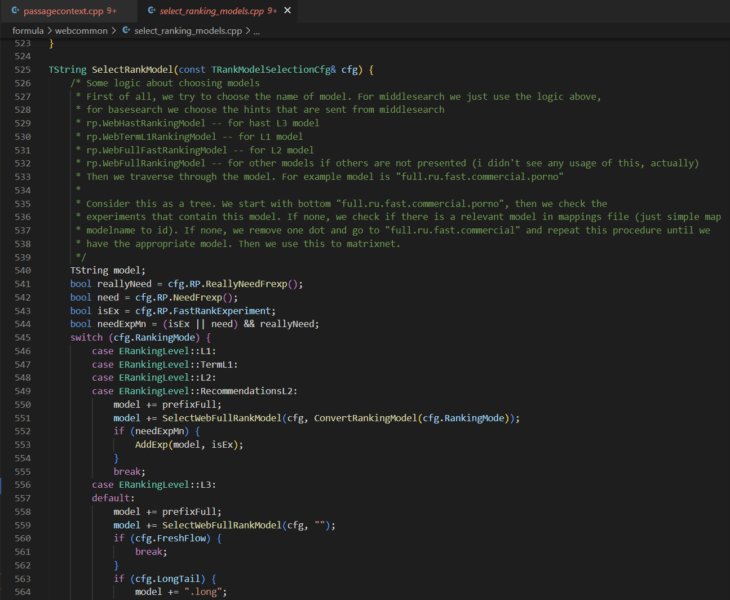
The selecting_rankings_model.cpp file means that completely different rating fashions could also be thought of at every layer all through the method. That is principally how neural networks work. Every degree is a side that completes operations and their mixed computations yield the re-ranked record of paperwork that finally seems as a SERP. I’ll observe up with a deep dive on MatrixNet when I’ve extra time. For people who want a sneak peek, take a look at the Search consequence ranker patent.
For now, let’s check out some fascinating rating components.
Prime 5 negatively weighted preliminary rating components
The next is an inventory of the best negatively weighted preliminary rating components with their weights and a short clarification primarily based on their descriptions translated from Russian.
- FI_ADV: -0.2509284637 -This issue determines that there’s promoting of any variety on the web page and points the heaviest weighted penalty for a single rating issue.
- FI_DATER_AGE: -0.2074373667 – This issue is the distinction between the present date and the date of the doc decided by a dater perform. The worth is 1 if the doc date is identical as right this moment, 0 if the doc is 10 years or older, or if the date will not be outlined. This means that Yandex has a desire for older content material.
- FI_QURL_STAT_POWER: -0.1943768768 – This issue is the variety of URL impressions because it pertains to the question. It appears as if they need to demote a URL that seems in lots of searches to advertise variety of outcomes.
- FI_COMM_LINKS_SEO_HOSTS: -0.1809636391 – This issue is the proportion of inbound hyperlinks with “industrial” anchor textual content. The issue reverts to 0.1 if the proportion of such hyperlinks is greater than 50%, in any other case, it’s set to 0.
- FI_GEO_CITY_URL_REGION_COUNTRY: -0.168645758 – This issue is the geographical coincidence of the doc and the nation that the consumer searched from. This one doesn’t fairly make sense if 1 signifies that the doc and the nation match.
In abstract, these components point out that, for the perfect rating, it is best to:
- Keep away from adverts.
- Replace older content material reasonably than make new pages.
- Ensure most of your hyperlinks have branded anchor textual content.
The whole lot else on this record is past your management.
Prime 5 positively weighted preliminary rating components
To observe up, right here’s an inventory of the best weighted constructive rating components.
- FI_URL_DOMAIN_FRACTION: +0.5640952971 – This issue is a wierd masking overlap of the question versus the area of the URL. The instance given is Chelyabinsk lottery which abbreviated as chelloto. To compute this worth, Yandex discover three-letters which can be lined (che, hel, lot, olo), see what quantity of all of the three-letter combos are within the area identify.
- FI_QUERY_DOWNER_CLICKS_COMBO: +0.3690780393 – The outline of this issue is that’s “cleverly mixed of FRC and pseudo-CTR.” There isn’t any quick indication of what FRC is.
- FI_MAX_WORD_HOST_CLICKS: +0.3451158835 – This issue is the clickability of an important phrase within the area. For instance, for all queries in which there’s the phrase “wikipedia” click on on wikipedia pages.
- FI_MAX_WORD_HOST_YABAR: +0.3154394573 – The issue description says “essentially the most attribute question phrase equivalent to the positioning, in keeping with the bar.” I’m assuming this implies the key phrase most looked for in Yandex Toolbar related to the positioning.
- FI_IS_COM: +0.2762504972 – The issue is that the area is a .COM.
In different phrases:
- Play phrase video games along with your area.
- Ensure it’s a dot com.
- Encourage folks to seek for your goal key phrases within the Yandex Bar.
- Hold driving clicks.
There are many surprising preliminary rating components
What’s extra fascinating within the preliminary weighted rating components are the surprising ones. The next is an inventory of seventeen components that stood out.
- FI_PAGE_RANK: +0.1828678331 – PageRank is the seventeenth highest weighted consider Yandex. They beforehand eliminated hyperlinks from their rating system fully, so it’s not too surprising how low it’s on the record.
- FI_SPAM_KARMA: +0.00842682963 – The Spam karma is called after “antispammers” and is the chance that the host is spam; primarily based on Whois data
- FI_SUBQUERY_THEME_MATCH_A: +0.1786465163 – How intently the question and the doc match thematically. That is the nineteenth highest weighted issue.
- FI_REG_HOST_RANK: +0.1567124399 – Yandex has a number (or area) rating issue.
- FI_URL_LINK_PERCENT: +0.08940421124 – Ratio of hyperlinks whose anchor textual content is a URL (reasonably than textual content) to the overall variety of hyperlinks.
- FI_PAGE_RANK_UKR: +0.08712279101 – There’s a particular Ukranian PageRank
- FI_IS_NOT_RU: +0.08128946612 – It’s a constructive factor if the area will not be a .RU. Apparently, the Russian search engine doesn’t belief Russian websites.
- FI_YABAR_HOST_AVG_TIME2: +0.07417219313 – That is the common dwell time as reported by YandexBar
- FI_LERF_LR_LOG_RELEV: +0.06059448504 – That is hyperlink relevance primarily based on the standard of every hyperlink
- FI_NUM_SLASHES: +0.05057609417 – The variety of slashes within the URL is a rating issue.
- FI_ADV_PRONOUNS_PORTION: -0.001250755075 – The proportion of pronoun nouns on the web page.
- FI_TEXT_HEAD_SYN: -0.01291908335 – The presence of [query] phrases within the header, considering synonyms
- FI_PERCENT_FREQ_WORDS: -0.02021022114 – The share of the variety of phrases, which can be the 200 most frequent phrases of the language, from the variety of all phrases of the textual content.
- FI_YANDEX_ADV: -0.09426121965 – Getting extra particular with the distaste in direction of adverts, Yandex penalizes pages with Yandex adverts.
- FI_AURA_DOC_LOG_SHARED: -0.09768630485 – The logarithm of the variety of shingles (areas of textual content) within the doc that aren’t distinctive.
- FI_AURA_DOC_LOG_AUTHOR: -0.09727752961 – The logarithm of the variety of shingles on which this proprietor of the doc is acknowledged because the writer.
- FI_CLASSIF_IS_SHOP: -0.1339319854 – Apparently, Yandex goes to present you much less love in case your web page is a retailer.
The first takeaway from reviewing these odd rankings components and the array of these accessible throughout the Yandex codebase is that there are a lot of issues that might be a rating issue.
I believe that Google’s reported “200 alerts” are literally 200 courses of sign the place every sign is a composite constructed of many different elements. In a lot the identical approach that Google Analytics has dimensions with many metrics related, Google Search probably has courses of rating alerts composed of many options.
Yandex scrapes Google, Bing, YouTube and TikTok
The codebase additionally reveals that Yandex has many parsers for different web sites and their respective providers. To Westerners, essentially the most notable of these are those I’ve listed within the heading above. Moreover, Yandex has parsers for a wide range of providers that I used to be unfamiliar with in addition to these for its personal providers.
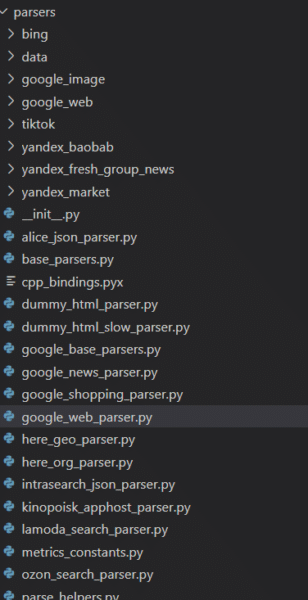
What is straight away evident, is that the parsers are characteristic full. Each significant element of the Google SERP is extracted. The truth is, anybody that could be contemplating scraping any of those providers may do nicely to evaluate this code.

There’s different code that signifies Yandex is utilizing some Google information as a part of the DSSM calculations, however the 83 Google named rating components themselves make it clear that Yandex has leaned on the Google’s outcomes fairly closely.
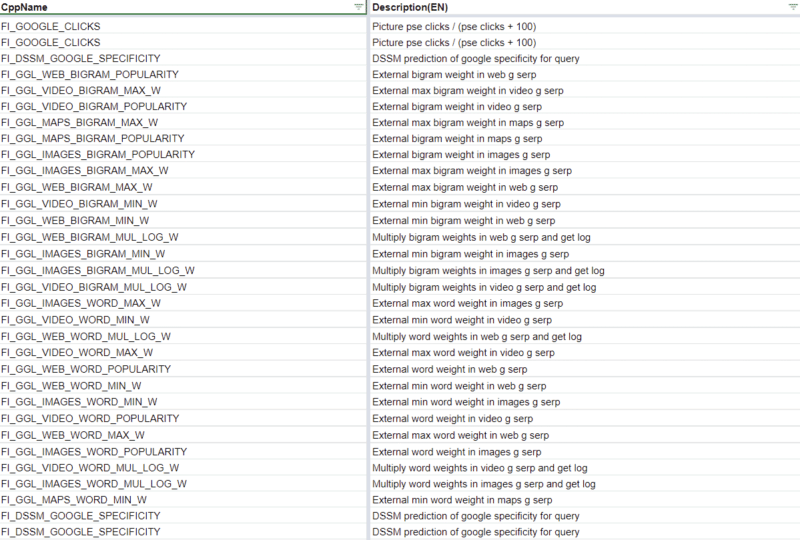
Clearly, Google would by no means pull the Bing transfer of copying one other search engine’s outcomes nor be reliant on one for core rating calculations.
Yandex has anti-Web optimization higher bounds for some rating components
315 rating components have thresholds at which any computed worth past that signifies to the system that that characteristic of the web page is over-optimized. 39 of those rating components are a part of the initially weighted components that will preserve a web page from being included within the preliminary postings record. You could find these within the spreadsheet I’ve linked to above by filtering for the Rank Coefficient and the Anti-Web optimization column.
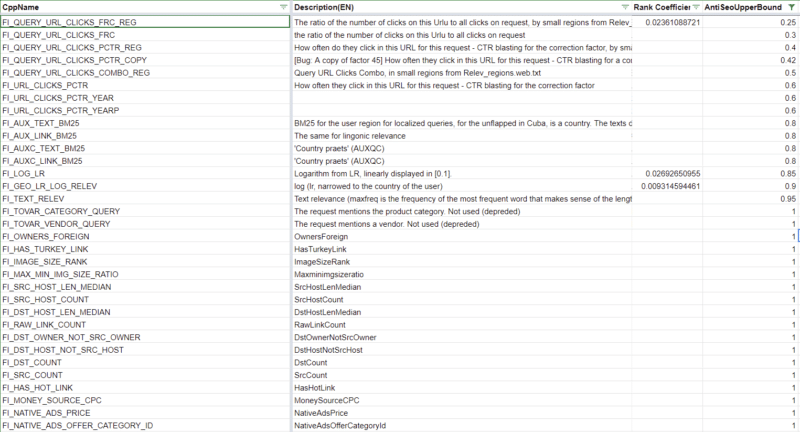
It’s not far-fetched conceptually to count on that each one fashionable engines like google set thresholds on sure components that SEOs have traditionally abused akin to anchor textual content, CTR, or key phrase stuffing. For example, Bing was stated to leverage the abusive utilization of the meta key phrases as a adverse issue.
Yandex boosts “Important Hosts”
Yandex has a collection of boosting mechanisms all through its codebase. These are synthetic enhancements to sure paperwork to make sure they rating greater when being thought of for rating.
Under is a remark from the “boosting wizard” which means that smaller information profit greatest from the boosting algorithm.

There are a number of kinds of boosts; I’ve seen one enhance associated to hyperlinks and I’ve additionally seen a collection of “HandJobBoosts” which I can solely assume is a bizarre translation of “guide” modifications.
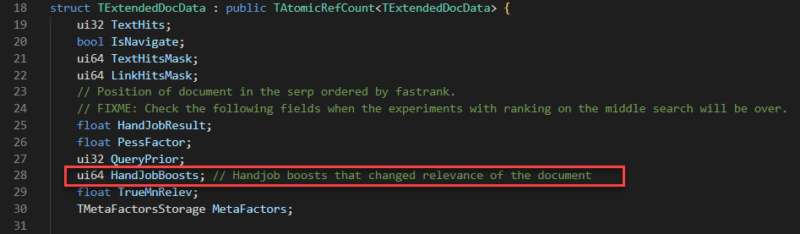
Considered one of these boosts I discovered notably fascinating is expounded to “Important Hosts.” The place a significant host may be any website specified. Particularly talked about within the variables is NEWS_AGENCY_RATING which leads me to consider that Yandex provides a lift that biases its outcomes to sure information organizations.

With out stepping into geopolitics, that is very completely different from Google in that they’ve been adamant about not introducing biases like this into their rating programs.
The construction of the doc server
The codebase reveals how paperwork are saved in Yandex’s doc server. That is useful in understanding {that a} search engine doesn’t merely make a duplicate of the web page and reserve it to its cache, it’s capturing varied options as metadata to then use within the downstream rankings course of.
The screenshot under highlights a subset of these options which can be notably fascinating. Different information with SQL queries counsel that the doc server has nearer to 200 columns together with the DOM tree, sentence lengths, fetch time, a collection of dates, and antispam rating, redirect chain, and whether or not or not the doc is translated. Essentially the most full record I’ve come throughout is in /robotic/rthub/yql/protos/web_page_item.proto.

What’s most fascinating within the subset right here is the variety of simhashes which can be employed. Simhashes are numeric representations of content material and engines like google use them for lightning quick comparability for the dedication of duplicate content material. There are numerous situations within the robotic archive that point out duplicate content material is explicitly demoted.

Additionally, as a part of the indexing course of, the codebase options TF-IDF, BM25, and BERT in its textual content processing pipeline. It’s not clear why all of those mechanisms exist within the code as a result of there may be some redundancy in utilizing all of them.
Hyperlink components and prioritization
How Yandex handles hyperlink components is especially fascinating as a result of they beforehand disabled their affect altogether. The codebase additionally reveals loads of details about hyperlink components and the way hyperlinks are prioritized.
Yandex’s hyperlink spam calculator has 89 components that it appears to be like at. Something marked as SF_RESERVED is deprecated. The place supplied, you could find the descriptions of those components within the Google Sheet linked above.


Notably, Yandex has a number rank and a few scores that seem to stay on long run after a website or web page develops a popularity for spam.
One other factor Yandex does is evaluate copy throughout a website and decide if there may be duplicate content material with these hyperlinks. This may be sitewide hyperlink placements, hyperlinks on duplicate pages, or just hyperlinks with the identical anchor textual content coming from the identical website.

This illustrates how trivial it’s to low cost a number of hyperlinks from the identical supply and clarifies how essential it’s to focus on extra distinctive hyperlinks from extra various sources.
What can we apply from Yandex to what we learn about Google?
Naturally, that is nonetheless the query on everybody’s thoughts. Whereas there are definitely many analogs between Yandex and Google, in truth, solely a Google Software program Engineer engaged on Search may definitively reply that query.
But, that’s the improper query.
Actually, this code ought to assist us increase our excited about fashionable search. A lot of the collective understanding of search is constructed from what the Web optimization group discovered within the early 2000s by way of testing and from the mouths of search engineers when search was far much less opaque. That sadly has not saved up with the speedy tempo of innovation.
Insights from the various options and components of the Yandex leak ought to yield extra hypotheses of issues to check and think about for rating in Google. They need to additionally introduce extra issues that may be parsed and measured by Web optimization crawling, hyperlink evaluation, and rating instruments.
For example, a measure of the cosine similarity between queries and paperwork utilizing BERT embeddings might be useful to grasp versus competitor pages because it’s one thing that fashionable engines like google are themselves doing.
A lot in the best way the AOL Search logs moved us from guessing the distribution of clicks on SERP, the Yandex codebase strikes us away from the summary to the concrete and our “it relies upon” statements may be higher certified.
To that finish, this codebase is a present that can carry on giving. It’s solely been a weekend and we’ve already gleaned some very compelling insights from this code.
I anticipate some bold Web optimization engineers with way more time on their palms will preserve digging and perhaps even fill in sufficient of what’s lacking to compile this factor and get it working. I additionally consider engineers on the completely different engines like google are additionally going by way of and parsing out improvements that they’ll be taught from and add to their programs.
Concurrently, Google legal professionals are in all probability drafting aggressive stop and desist letters associated to all of the scraping.
I’m desirous to see the evolution of our area that’s pushed by the curious individuals who will maximize this chance.
However, hey, if getting insights from precise code will not be useful to you, you’re welcome to return to doing one thing extra essential like arguing about subdomains versus subdirectories.
Opinions expressed on this article are these of the visitor writer and never essentially Search Engine Land. Employees authors are listed right here.

{kind=link}